CT Scheme and ERA Scheme
The Cross-Target (CT) Method
To develop our agent based experiments, we introduce the following general hypothesis (GH): an agent, acting in an economic environment, must develop and adapt her capability of evaluating, in a coherent way, (1) what she has to do in order to obtain a specific result and (2) how to foresee the consequences of her actions. The same is true if the agent is interacting with other agents. Beyond this kind of internal consistency (IC),agents can develop other characteristics, for example the capability of adopting actions (following external proposals, EPs)or evaluations of effects (following external objectives, EOs)suggested from the environment (for example, following rules) orfrom other agents (for examples, imitating them). Those additional characteristics are useful for a better tuning of the agents in making experiments.
To apply the GH we are employing here artificial neural networks; we observe, anyway, that the GH can be applied using other algorithms and tools, reproducing the experience-learning-consistency-behavior cycle with or without neural networks.
An introductory general remark: in all the cases to which we have applied our GH, the preliminary choice of classifying agents' output in actions and effects has been useful (i) to clarify the role of the agents, (ii) to develop model plausibility and results, (iii) to avoid the necessity of prior statements about economic rational optimizing behavior (Beltratti et al. 1996).
Economic behavior, simple or complex, can appear directly as a by-product of IC, EPs and EOs. To an external observer, ourArtificial Adaptive Agents (AAAs) are apparently operating with goals and plans. Obviously, they have no such symbolic entities,which are inventions of the observer. The similarity that we recall here is that the observations and analyses about real world agents' behavior can suffer from the same bias. Moreover,always to an external observer, AAAs can appear to apply the rationality paradigm, with maximizing behavior.
The main problem is: obviously agents, with their action, have the goal of increasing or decreasing something, but it is not correct to deduce from this statement any formal apparatus encouraging the search for complexity within agents, not even in the as if perspective. With our GH, and hereafter with theCross Target (CT) method, we work at the edge of Alife techniques to develop Artificial Worlds of simple bounded rationality AAAs:from their interaction, complexity, optimizing behavior andOlympic rationality can emerge, but externally to the agents.
In order to implement this ideal target without falling in the trap of creating models that are too complicated to be managed,we consider artificially intelligent agents founded upon algorithms which can be modified by a trial and error process. In one sense our agents are even simpler than those considered in neoclassical models, as their targets and instruments are not as powerful as those assumed in those models. From another point of view, however, our agents are much more complex, due to their continuous effort to learn the main features of the environment with the available instruments.
The name cross-targets (CTs) comes from the technique used to figure out the targets necessary to train the ANNs representing the artificial adaptive agents (AAAs) that populate our experiments.
Following the GH, the main characteristic of these AAAs is that of developing internal consistency between what to do and the related consequences. Always according to the GH, in many (economic)situations, the behavior of agents produces evaluations that can be split in two parts: data quantifying actions (what to do) and forecasts of the outcomes of the actions. So we specify two types of outputs of the ANN and, identically, of the AAA: (i) actions to be performed and (ii) guesses about the effects of those actions.
Both the targets necessary to train the network from the point of view of the actions and those connected with the effects are built in a crossed way, originating the name Cross Targets. The former are built in a consistent way with the outputs of the network concerning the guesses of the effects, in order to develop the capability to decide actions close to the expected results. The latter, similarly, are built in a consistent way with the outputs of the network concerning the guesses of the actions,in order to improve the agent's capability of estimating the effects emerging from the actions that the agent herself is deciding.
CTs, as a fulfillment of the GH, can reproduce economic subjects' behavior, often in internally ingenuous ways, but externally with complex results.
The method of CTs, introduced to develop economic subjects' autonomous behavior, can also be interpreted as a general algorithm useful for building behavioral models without using constrained or unconstrained optimization techniques. The kernel of the method, conveniently based upon ANNs (but it could also be conceivable with the aid of other mathematical tools), is learning by guessing and doing: the subject control capabilities can be developed without defining either goals or maximizing objectives.
We choose the neural networks approach to develop CTs, mostly as a consequence of the intrinsic adaptive capabilities of neural functions. Here we will use feed forward multilayer networks.
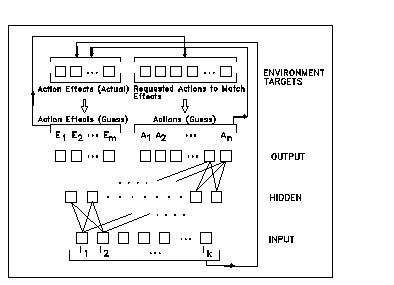
Figure 1 describes an AAA learning and behaving in a CT scheme.The AAA has to produce guesses about its own actions and related effects, on the basis of an information set (the input elements are I1,...,Ik). Remembering the requirement of IC, targets in learning process are: (i) on one side, the actual effects -measured through accounting rules - of the actions made by the simulated subject; (ii) on the other side, the actions needed to match guessed effects. In the last case we have to use inverse rules, even though some problems arise when the inverse is indeterminate.
A first remark, about learning and CT: analyzing the changes of the weights during the process we can show that the matrix of weights linking input elements to hidden ones has little or no changes, while the matrix of weights from hidden to output layer changes in a relevant way. Only hidden-output weight changes determine the continuous adaptation of ANN responses to the environment modifications, as the output values of hidden layer elements stay almost constant. This situation is the consequence both of very small changes in targets (generated by CT method)and of a reduced number of learning cycles.
The resulting network is certainly under trained:consequently, the simulated economic agent develops a local ability to make decisions, but only by adaptations of outputs to the last targets, regardless to input values. This is short term learning as opposed to long term learning.
Some definitions: we have (i) short term learning, in the acting phase, when agents continuously modify their weights (mainly from the hidden layer to the output one), to adapt to the targets self-generated via CT; (ii) long term learning, ex post, when we effectively map inputs to targets (the same generated in the acting phase) with a large number of learning cycles, producingANNs able to definitively apply the rules implicitly developed in the acting and learning phase.
A second remark, about both external objectives (EOs) and external proposals (EPs): if used, these values substitute the cross targets in the acting and adapting phase and are consistently included in the data set for ex post learning.Despite the target coming from actions, the guess of an effect can be trained to approximate a value suggested by a simple rule,for example increasing wealth. This is an EO in CT terminology.Its indirect effect, via CT, will modify actions, making them more consistent with the (modified) guesses of effects. Viceversa, the guess about an action to be accomplished can be modified via an EP, affecting indirectly also the corresponding guesses of effects. If EO, EP and IC conflict in determining behavior, complexity may emerge also within agents, but in abounded rationality perspective, always without the optimization and full rationality apparatus.
Figure 1
The Environment-Rules-Agents (ERA) scheme
Swarm is a natural candidate to this kind of structures, but we need some degree of standardization, mainly when we go from simple models to complex results. Here a crucial role for the usefulness and the acceptability of the experiments is played by the structure of the underlying models. For this reason, we introduce here a general scheme that can be employed in building agent-based simulations.
The main value of the Environment-Rules-Agents (ERA) scheme,introduced in Gilbert and Terna (2000) and shown in Figure 2, is that it keeps both the environment, which models the context by means of rules and general data, and the agents, with their private data, at different conceptual levels. To simplify the code, we suggest that agents should not communicate directly, but always through the environment; as an example, the environment allows each agent to know the list of its neighbors. This is not mandatory, but if we admit direct communication between agents,the code becomes more complex.
With the aim of simplifying the code design, agent behavior is determined by external objects, named Rule Masters, that can be interpreted as abstract representations of the cognition of the agent. Production systems, classifier systems, neural networks and genetic algorithms are all candidates for the implementation of Rule Masters.
We may also need to employ meta-rules, i.e., rules used to modify rules (for example, the training side of a neural network).The Rule Master objects are therefore linked to Rule Maker objects, whose role is to modify the rules mastering agent behavior, for example by means of a simulated learning process.Rule Masters obtain the information necessary to apply rules from the agents themselves or from special agents charged with the task of collecting and distributing data. Similarly, Rule Makers interact with Rule Masters, which are also responsible forgetting data from agents to pass to Rule Makers.
Agents may store their data in a specialized object, theDataWarehouse, and may interact both with the environment and other agents via another specialized object, the Interface (DataWarehouse and Interface are not represented in Figure 2, having a simple one to one link with their agent; they are used in the bp-ct package and in its derivatives).
Although this code structure appears to be complex, there is a benefit when we have to modify a simulation. The rigidity of the structure then becomes a source of invaluable clarity. An example of the use of this structure can be found in the code of theSwarm application bp-ct in which the agents are neural networks;also the specialized code related to the hayekian experiment reported in ct-hayek code, being built upon bp-ct, uses the same structure
A second advantage of using the ERA structure is its modularity, which allows model builders to modify only the RuleMaster and Rule Maker modules or objects whenever one wants to switch from agents based on neural networks, to alternatives such as production systems, classifier systems or genetic algorithms.
In Swarm terms, the Environment coincides with the ModelSwarm object, while the ObserverSwarm object is external to this structure.
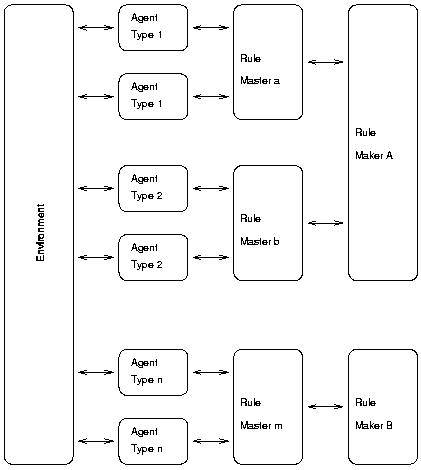
Figure 2
More details about CT and ERA can be found in Terna (2000).
Beltratti, A., Margarita, S., Terna, P.
Gilbert N., Terna P. (2000), How to build anduse agent-based models in social science, Mind & Society,no. 1, 2000.
Terna P. (2000), Economic Experiments withSwarm: a Neural Network Approach to the Self-Development ofConsistency in Agents' Behavior, in F. Luna and B. Stefansson (eds.),Economic Simulations in Swarm: Agent-Based Modelling and ObjectOriented Programming. Dordrecht and London, Kluwer Academic,2000.